服务器、超算使用教程¶
约 3659 个字 653 行代码 3 张图片 预计阅读时间 20 分钟
服务器、超算介绍¶
Master¶
- Linux 系统:Ubuntu 22.04,内核:5.19.0-43-generic
- root 权限:无;无法使用 apt、apt-get、dpkg、snap 命令安装程序
- 作业调度系统:Slurm
- CPU:2 \(\times\) 32 核 Intel Xeon Platinum 8369B,共 64 核
- GPU:2 \(\times\) 24G RTX 3090;调用 GPU 时只能一整块调用,显存自动分配
- Intel 套件:Intel-oneAPI 2022.1.0
- 内存:共 512G
- 数据存储:较大体积的数据(Master 本地或超算上的)可以放到
${HOME}/storage /home/share目录,不同用户可将临时共享文件放此,所有用户可删除文件,但文件夹需其所有者才能删除,因此建议将文件夹进行打包压缩再放到 share 目录中
cat /proc/cpuinfo # CPU 信息查看;或 lscpu
cat /proc/meminfo # 内存信息查看;lsmem
free -gh # 内存使用情况查看(以 GB 为单位)
nvidia-smi # GPU 信息、使用情况查看
nvidia-smi -L # 显示连接的 GPU 信息
# 查看物理 CPU 数目(几块 CPU)
lscpu | grep Sock
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
# 查看逻辑 CPU 数目(CPU 有几个核)
lscpu | grep sock
lscpu | grep -E '^CPU\(s\):'
cat /proc/cpuinfo | grep "processor" | wc -l
nproc
# 查看系统负载
top
htop
uptime
vmstat
# 赝势路径
/work/backup/.vasp_pot # Master
/opt/.vasp_pot # Manager
- Master 上已安装的孔老师的程序/软件:
cat /opt/bin/README查看
# Code Function
ave....................Get the averages of data columns in a file
bave...................Get the block averages of data columns in a file
binave.................Get the bin averages of data columns in a file
crysinfo...............Get the crystalline symmetry info for an xyz file
cumsum.................Get the cummulative sum of data columns in a file
d2p....................Dump2phonon, get dynamical matrix from a lammps trajectory file
dos2th.................Get thermal info from phonon DOSes.
dumpana................Analyze the lammps dump file
find-min-pos...........Find the location (line #) of a minimum value within a column data
find-val-pos...........Find the location of a given value within a column data
get-col-num............Get the column number of a word in the first line of the file.
getpot.................Get vasp potential for desired elements.
gsub...................Submit GPU jobs.
hist...................Get the histogram of a data file.
histjoin...............To join multiple files from hist.
latgen.................To generate the position file for selected crystals.
lmp....................LAMMPS
mathfun................To perform simple math calculations.
ovito..................To visualize atomic configurations.
phana..................To analyze binary file from fix-phonon.
posconv................To convert formats of pos files
run....................To find the locations of running jobs.
spave..................To get the spatial average from data columns in a file
submit.................To submit CPU jobs.
v6.gam.................vasp.6.3.0.gam
v6.ncl.................vasp.6.3.0.ncl
v6.std.................vasp.6.3.0.std
vacf...................To measure phonon DOS based on velocity-velocity autocorrelation function method
vasp...................vasp.5.4.4.std
vasp.5.gam.............vasp.5.4.4.gam
vasp.5.std.............vasp.5.4.4.std
vasp.6.gpu.............vasp.6.3.0.std.gpu (OpenACC)
vasp.6.gpu.gam.........vasp.6.3.0.gam.gpu
vasp_gam...............vasp.5.4.4.gam
vaspkit................Toolkit for vasp calculations.
vasp_std...............vasp.5.4.4.std
viscal.................To calculate shear viscosity based on Green-Kubo method
vmd....................To visualize md trajectories
Intel Xeon CPU 相关¶
-
Intel 至强处理器的数字和后缀可以表示性能、功能和代次 英特尔® 至强® 可扩展处理器编号和后缀
- 四位数字序列的第一个数字表示处理器级别:8、9 铂;
- 第二个数字表示处理器代次:1-6
- 第三位和第四位数字表示 SKU 编号:这些数字不代表任何特定功能。通常,性能越好的处理器具有较大的 SKU 编号
GPU 相关¶
-
注意事项:
- 用 slurm 提交 GPU 任务,某一块 GPU 则会被该任务独占(不过不影响在终端 / tmux 中直接运行 GPU 任务)
-
GPU 任务也是要占用 CPU 的,需做好资源分配(不添加 -N、--ntasks-per-node 时,默认会使用 1 个 CPU 核)
-
llm_note/4-hpc_basic/英伟达GPU架构总结.md at main · harleyszhang/llm_note · GitHub(含 V100、A100、H100 GPU 介绍)
-
NVIDIA GPU 参数:
- CUDA Core(NVIDIA GPU 的计算核心单元)
- Tensor Core(专门用于深度学习作业中的张量计算)
- RT Core(加速光线追踪计算)
-
NVIDIA GPU 架构:Volta(伏特,第 6 代)、Turing(图灵,第 7 代)、Ampere(安培、第 8 代)、Hopper(霍珀,第 9 代)
-
V100、A800(A100 中国特供版)、H800(H100 中国特供版)
-
查看 CUDA 是否安装(分为两种,驱动 driver 和运行 runtime)
nvidia-smi # 查看 NVIDIA 驱动及其支持的 CUDA 驱动最高版本
nvidia-smi -L # GPU 数量和型号
nvcc --version # 查看 CUDA 运行版本(Master 上显示的路径在 hpc_sdk中)
/usr/local/cuda # CUDA 安装路径
-
GPU 信息及使用情况查看:
nvidia-smi、gpustat - Python
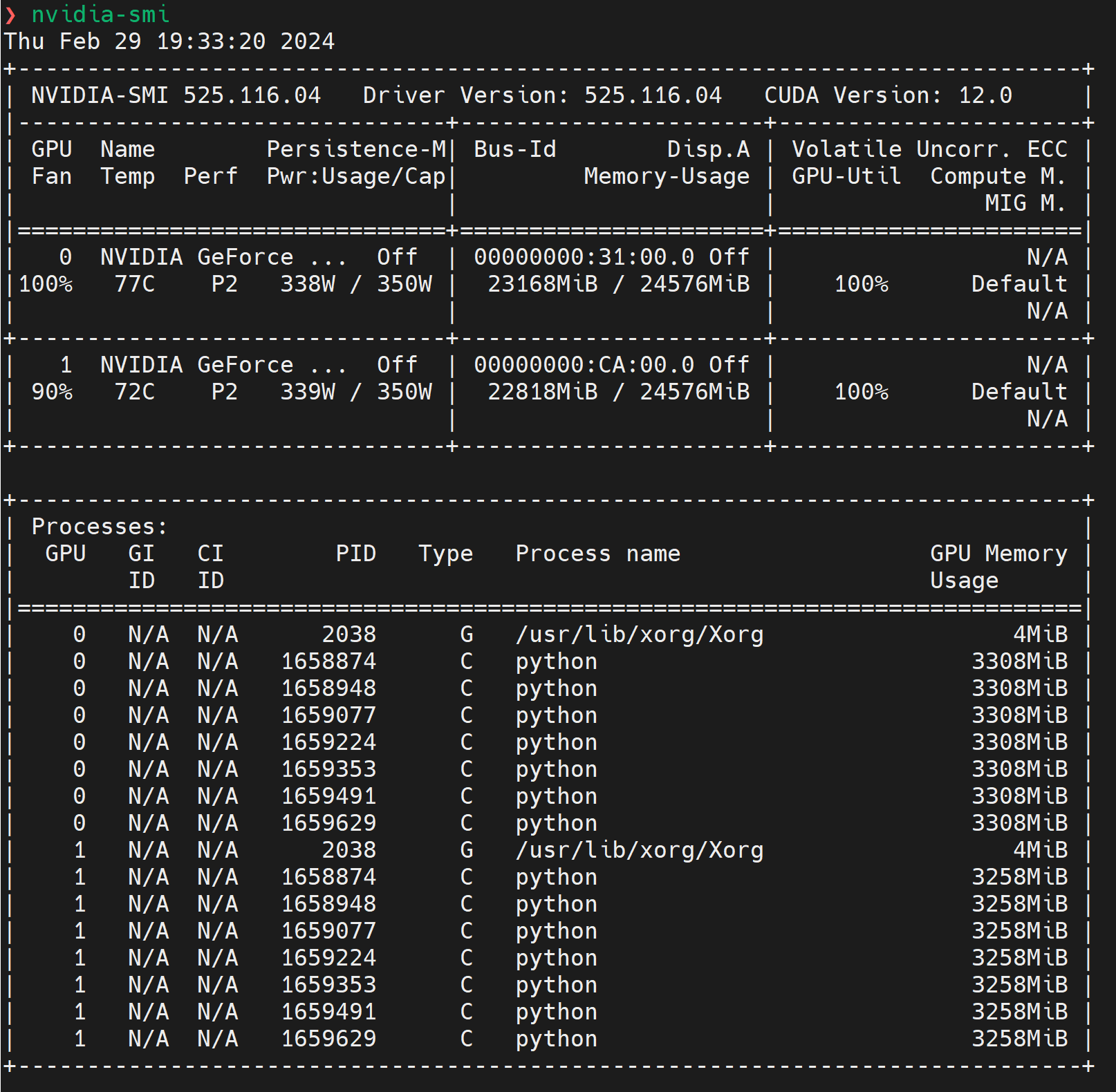
- 输出信息解读:两个 GPU 都在高负载运行(GPU 利用率 100%,温度分别为 77 摄氏度和 72 摄氏度),并且接近其功率上限。GPU 上的内存几乎被完全利用,表明运行的进程正在积极使用 GPU 资源
# GPU 列表
GPU 0 / GPU 1 # 系统中有两个 NVIDIA GeForce 系列的 GPU
Persistence-M # 显示 GPU 的持久模式是否开启
Bus-Id # 显示 GPU 在系统总线上的唯一标识符,可以用于特定应用配置
Disp.A # 显示是否用作显示输出
Volatile Uncorr. ECC # 显示易失性未校正的 ECC(错误校正码)错误
Fan # GPU 风扇速度
Temp # GPU 温度
Perf # 性能状态,P2 表示当前在一种性能状态
Pwr:Usage/Cap # 当前功率使用量和功率上限
Memory-Usage # GPU 内存使用情况
GPU-Util # GPU 使用率
Compute M. # 计算模式,默认是 Default
# 进程:列出了在每个 GPU 上运行的进程
PID # 进程 ID
Type # 进程类型,G 表示图形,C 表示计算
Process name # 进程名称
GPU Memory Usage # 进程使用的 GPU 内存量
- 指定使用哪块 GPU(适用于 TensorFlow 和 PyTorch 等任何使用 CUDA 的程序)
Manager¶
- Linux 系统:Ubuntu 16.04;内核:4.15.0-120-generic
- root 权限:无;无法使用 apt、apt-get、dpkg、snap 命令安装程序
- 作业调度系统:PBS
- CPU:Intel Xeon E5520、Intel Xeon E5630(node 9)、Intel Xeon E5-2620(node 11);共 100 核,共 12 个节点(node1~11 + manager;其中 node2,6,7,8 经常 down)
- GPU:Matrox Electronics Systems Ltd. MGA G200eW WPCM450、XGI Technology Inc. XG20 core(前两者主要用于服务器的视频输出和基本图形处理作业)、2 \(\times\) 4.6G NVIDIA Tesla K20m(node 11)
- 内存:登录、Manager 节点约 4G;node 11 约 16G;node 1, 3-5 约 24G;node 9-10 约 16G
- Intel 套件:Composer XE 2015
- glibc 版本过低(编译安装新版本较为复杂)
超算¶
- 计算系统 - 上海交大超算平台用户手册
- Linux 系统:Rocky Linux(基于 Centos)
- root 权限:无;无法使用 yum 命令安装软件程序
- 作业调度系统:Slurm;Pi、ARM、思源一号提交的作业在任一平台都可以看到
- CPU、内存:超算中的 CPU 核有内存配比限制
- GPU:超算的 GPU 队列很难排到
- 程序/软件:Pi 的一些基础程序的版本比思源一号旧许多;查看:
module av - Pi 和 ARM 用户目录相同
- sylogin1 登录节点占用率较高,比其他(2-5)卡,是超算断开连接,vim 使用卡顿的可能原因之一;超算的登录节点为随机分配,应尽量避免登录到 sylogin1
服务器、超算登录¶
SSH 登录¶
-
超算平台的 SSH 端口均为默认值 22,
-p 22可省略 -
登录密码输错 5 词,需等待一段时候才能再次登录
# manager
ssh [email protected] -p 312
# master
ssh [email protected] -p 313
# 思源一号
ssh [email protected]
# Pi(cpu 队列)
ssh [email protected]
# Pi(centos 队列)
ssh [email protected]
# ARM
ssh [email protected]
终端 SSH 免密登录¶
-
上海交通大学超算管理系统:HAM
-
交大超算登录现需要与 jAccount 绑定:账号安全信息管理 - 上海交大超算平台用户手册 Documentation
-
无需输入用户名和密码即可登录,还可以作为服务器的别名来简化使用。免密登录需建立从远程主机(集群的登录节点)到本地主机的 SSH 信任关系。建立信任关系后,双方将通过 SSH 密钥对进行身份验证。
-
在本地主机上生成的 SSH 密钥对,输入以下命令,持续 Enter 即可;将在
~/.ssh(或C:\User\username\.ssh) 路径下生成密钥对文件id_rsa和id_rsa.pub;将id_rsa.pub的内容(注意字符之间只有一个空格,复制后需注意)添加到远程主机的~/.ssh/authorized_keys文件中。
-
密钥对生成方式有 ssh-keygen 和 putty(ppk 格式,WinSCP 软件密钥验证需该格式),其中后者可通过 Mobaxterm 软件中 tool 工具中的 MobaKeyGen 来生成(在空白处乱按加快生成速度;将生成的公钥保存成 file.pub,私钥保存成 file.ppk)。
-
~/.ssh/authorized_keys文件是 SSH 服务端用于验证客户端公钥的文件,每行一个公钥 -
设置服务器别名:编辑或创建
~/.ssh/config(或C:\User\XXX\.ssh\config)
- 具体示例:
Host Manager
HostName 202.120.55.11
User username
Port 312
IdentityFile ~/.ssh/id_rsa
Host Master
HostName 202.120.55.11
User username
Port 313
IdentityFile ~/.ssh/id_rsa
Host Pi
HostName pilogin.hpc.sjtu.edu.cn
User username
Port 22
IdentityFile ~/.ssh/id_rsa
Host SiYuan
HostName sylogin.hpc.sjtu.edu.cn
User username
Port 22
IdentityFile ~/.ssh/id_rsa
- 设置完成后,只需输入以下内容即可实现服务器、超算 SSH 登录:
- 可能会出现的问题
- SSH 私钥的权限过于开放:SSH 私钥文件应该只能被文件的拥有者读取和写入,而不能被其他用户访问
- 解决方法:
chmod 600 id_rsa
Permissions 0444 for 'id_rsa' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
Load key "id_rsa": bad permissions
客户端免密登录¶
-
常用软件:MobaXterm、Tabby(有 交我算定制版客户端) 等。
-
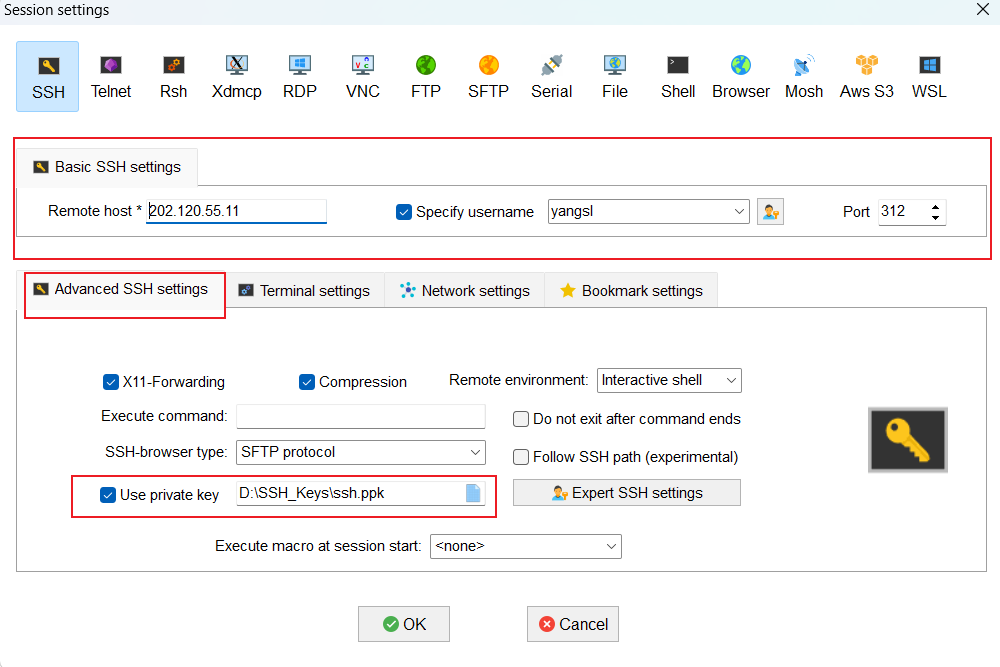
免密登录操作:将
id_rsa私钥文件所在路径添加到 Use private key 选项中(Bookmark settings 选项可以将默认的 Session name 改成自己想要的别名)。
VSCode 免密登录¶
-
安装 Remote Development 扩展,如上面的
~/.ssh/config内容已设置好,会自动识别设置好的主机名(config 文件所在路径可自定义) -
VSCode 远程连接 Manager(机子较老,10 余年历史),有时会导致其负载过高而崩溃,不建议长时间连接;VSCode 远程连接 Master(2023 年 5 月配置)暂无相关问题
-
在超算上使用 Python 插件中的 Pylance 语言服务器(LSP)以及 Jupyter 插件,常会出现 Pylance 崩溃的问题(Pi 稍微稳定些),因为超算的登录节点资源有限,建议将 Pylance 换成 Jedi(功能不及 Pylance),会稍微稳定些;建议不在超算平台上使用 Jupyter Notebook;Master 暂无相关问题
跳板¶
-
SSH 通过跳板机(登录节点)直接访问内网机器(计算节点)
-
SSH config 中的 RemoteCommand 命令实际作用不大,不建议使用
# 查看(内网)IP 地址
hostname -I
ip a | grep inet
ss -tuln # 查看有哪些端口正在监听
Host login
HostName login_ip
User username
Port ...
IdentityFile ~/.ssh/id_rsa
Host target
HostName ip_target
User username_target
Port ...
IdentityFile ~/.ssh/id_rsa
ProxyJump login # 关键参数
作业准备、提交、检查¶
Slurm 作业调度系统¶
-
Slurm 无法指定 CPU 核由具体单独的一颗 CPU 全部提供;How to ask SLURM scheduler for CPUs on the same socket/NUMA node? - Stack Overflow(该 URL 并未提供解决方案)
# 基本术语
socket # CPU 插槽,可简单理解为 CPU
core # CPU 核,单颗 CPU 可以具有多颗 CPU 核
job # 作业
job step # 作业步,单个作业(job)可以有个多作业步
tasks # 作业数,单个作业或作业步可有多个作业,一般一个作业需一个 CPU 核,可理解为所需的 CPU 核数
rank # 秩,如 MPI 进程号
# 常用命令
sbatch job.slurm # 提交作业
squeue # 查看作业状态
scancel # 删除作业
scontrol # 查看作业详细状态
sinfo # 查看集群状态(显示队列、节点信息)
scontrol show job # 所有作业详细状态
scontrol show job JobId # 指定作业详细状态
scontrol show node NodeName # 节点详细状态
sinfo --partition=64c512g # 查看特定队列
# 需要 root 用户进行操作
scontrol suspend JobId # 挂起作业(释放资源)
scontrol resume JobId # 恢复作业
# 修改排队作业的所需 CPU 核数、指定节点、排除节点、优先级(也可修改其他作业参数)
scontrol update JobId=... NumTasks=...
scontrol update JobId=... NumCPUs=...
# 指定 2 个节点时会出现问题,建议只指定 1 个节点
scontrol update JobId=... NodeList=... ExcNodeList=...
# 默认 SLURM 的优先级值范围是 0 到 4294967295(即 2³²−1),值越大,优先级越高
# 需管理员权限
scontrol update JobId=... Priority=...
# 格式化输出队列、节点信息
sinfo -o "%.15P %.6D %.7G %.7t %.14C %.10e %.9O"
%c # 每个节点的 CPU 数目
%C # 每个节点的 CPU 数目,以 "allocated/idle/other/total" 格式
%D # 节点数
%e # 总内存,单位 MB
%G # 与节点关联的 GPU 资源
%N # 节点名称
%O # CPU 负载
%P # 队列名称
%t # 节点状态,紧凑形式
# 示例 Master
PARTITION NODES GRES STATE CPUS(A/I/O/T) FREE_MEM CPU_LOAD
CLUSTER 1 gpu:2 mix 16/48/0/64 475653 43.01
cpu 1 (null) alloc 120/0/0/120 241975 120.00
cpu 1 gpu:1 alloc 120/0/0/120 159938 120.00
# sinfo 节点状态
idle # 节点处于空闲状态
mix # 节点部分 CPU 资源被占用
alloc # 节点所有 CPU 资源都被占用
down # 节点故障暂不可用
drain # 节点故障,但不影响已运行的作业
# squeue 作业状态
R # RUNNING;正在运行
PD # PENDING;正在排队
CG # 即将完成
CD # COMPLETED;已完成
F # FAILED;运行失败
S # SUSPENDED;挂起
CA # CANCELED;作业被取消
TO # TIMEOUT;超时
# 显示正在运行的作业信息(JobId STATE WORK_DIR)
squeue -t RUNNING --format "%.9i %.8T %Z"
# 查看一周内提交至 Slurm 队列系统的已完成作业信息(完善该 Shell 脚本,参数设为天数)
sacct --starttime=2025-04-05 --endtime=2025-04-12 --state=COMPLETED --format=JobID,JobName,State,Start,End,Elapsed,Workdir
JobID # 作业 ID
JobName # 作业名称
State # 状态
Start # 开始时间
End # 结束时间
Elapsed # 耗时
Workdir # 工作目录
PBS 作业调度系统¶
-
Manager 中的
submit命令是孔老师写的一个 PBS 作业提交脚本 -
-nc参数含义:不将文件复制到计算节点中;推荐用带-nc参数的命令 -
提交作业命令会自动生成对应的
PBS.batch脚本;当提交的作业出错时,修改PBS.batch脚本内容,之后可使用qsub PBS.batch命令提交作业
# 常用命令
pbsnodes # 查看所有节点
pbsnodes -l free # 查看空闲节点
pbsnodes XXX # 查看某节点状态
ssh XXX # 转到某节点
qsub script.pbs # 提交作业
qdel JOBID # 删除作业
qstat # 显示所有作业的状态
-u XXX # 指定用户
-f JOBID # 指定作业的详细状态
-a # 所有作业的详细状态
-n # 节点状态
-q / -Q # 队列状态
-B # 服务器状态
-r # 正在运行的作业
-i # 正在等待的作业
-x # 已完成的作业
# VASP 作业提交命令
submit -nc -n 8 vasp
submit -n 8 vasp
# LAMMPS 作业提交命令
submit -nc -n 8 lmp -in in.file
submit -n 8 lmp -in in.file
# 或进入到计算节点本地运行
ssh manager
mpirun -n 1 lmp -in in.file
# pbs 提交脚本内容
#!/bin/sh
#PBS -N task
#PBS -l nodes=1:ppn=1
- Manager 中与 PBS 相关的一些 alias 设置
# 查看 q 相关命令 alias
alias | grep ^q
# q 相关命令均由 qstat 延伸
alias q='qstat -u xxx'
alias qq='pestat'
alias qa='qstat -a'
alias qn='qstat -u xxx|wc -l|awk '\\''{if ($1>0) print "Number of jobs by xxx: " $1-5; else print "Number of jobs by xxx: 0"}'\\'';qstat -a|wc -l|awk '\\''{print "Number of jobs by all: " $1-5}'\\'''
# q 相关命令
qstat # 查看所有作业的状态
qa # 查看所有作业的状态(信息比 qstat 详细)
q # 查看自己作业的状态
qq # 查看计算节点的状态(excl 正在运行;free 空闲;down 出现故障)
run # 查看自己作业的结果输出路径和信息
qn # 查看自己提交作业的数量和 manager 目前已提交的作业总数
ssh node02 # 连接计算节点;作业到了截止时间后程序会终止,只会输出 error 和 out 文件,可通过 ssh node 节点到计算该作业的节点中去,在 scratch 目录中可以找到该作业计算的结果
# 计算时间
Elap Time # 实际时间(小时: 分)
Req'd Time # 截止计算时间(240 小时)
Time Use # 实际时间 * 节点数
超算队列介绍¶
-
超算队列内存情况
- arm128c256g 每核 2G 内存 arm
- 64c512g 每核 8G 内存 siyuan
- cpu 每核 4G 内存 pi
- small 每核 4G 内存 pi
- dgx2 每核 6G 内存 pi
- huge 每核 35G 内存 pi
- 192c6t 每核 31G 内存 pi
- cpu,small 和 dgx2 队列作业运行时间最长 7 天,huge 和 192c6t 最长 2 天。作业延长需发邮件申请,附上用户名和作业 ID,延长后的作业最长运行时间不超过 14 天
-
队列资源选择
- 若是大规模的 CPU 作业,可选择 CPU 队列或思源一号 64c512g 队列,支持万核规模的并行
- 若是小规模测试,可选 small 队列或思源一号 64c512g 队列
- GPU 作业请至 dgx2 队列或思源一号 a100 队列
- 大内存作业可选择 huge 或 192c6t 两种队列
-
192c6t 和 huge 大内存队列,核数有一定要求,且排队时间较长
# 192c6t 队列
sbatch: error: The cpu demand is lower than 48. Please submit to huge or cpu partition.
sbatch: error: Batch job submission failed: Unspecified error
# huge 队列
sbatch: error: The cpu demand is lower than 6. Please submit to small partition.
sbatch: error: Batch job submission failed: Unspecified error
- 超算收费情况(2023.05.30)
交我算平台集群总费用为CPU,GPU和存储费用之和。费率标准如下:
CPU 价格:0.04元/核/小时(Pi 2.0集群 cpu/small/huge/192c6t/debug 队列) # 0.02 2025.03.30
0.05 元/核/小时(思源一号集群 64c512g 队列) # 0.03 2025.03.30
0.01元/核小时(arm128c256g队列)
GPU 价格:2 元/卡/小时(dgx2队列 V100 GPU)
2.5 元/卡/小时(思源一号 a100队列 A100 GPU)
免费存储 3 TB,超出部分 200 元/TB/年(存储按天扣费)
每个新账户赠送价值 300 元的积分,供免费试用
module avail/av # 查看超算预部署软件模块
module av [MODULE] # 查看具体模块
module load [MODULE] # 加载相应软件模块
module unload [MODULE] # 卸载相应软件模块
module list # 列出已加载模块
module purge # 清除所有已加载软件模块
module show [MODULE] # 列出该模块的信息,如路径(lib include 等)、环境变量等
作业提交示例¶
- SBATCH 参数
--job-name=[name] # 或 -J;作业名称
--nodes=[count] # 或 -N;节点数
--ntasks=[count] # 或 -n;该作业使用的 CPU 核数
--ntasks-per-node=[count] # 每个节点使用的 CPU 核数;--ntasks 参数的优先级高于该参数
--partition [partition] # 或 -p;指定队列
--output=[file_name] # 或 -o;标准输出文件
--error=[file_name] # 或 -e;标准错误文件
--time=[dd-hh:mm:ss] # 或 -t;允许作业运行的最大时间
--exclusive # 独占节点(应尽可能避免)
--nodelist=[nodes] # 或 -w;指定节点
--exclude=[nodes] # 或 -x;排除指定节点
VASP¶
#!/bin/bash
#SBATCH -J VASP
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
ulimit -s unlimited
# 思源
module load vasp/5.4.4-intel-2021.4.0
# module load vasp/6.2.1-intel-2021.4.0-cuda-11.5.0
mpirun vasp_std
# 自行编译的 VASP
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mpi/2021.4.0
module load intel-oneapi-mkl/2021.4.0
mpirun ${HOME}/bin/vasp_std
LAMMPS¶
#!/bin/bash
#SBATCH -J LAMMPS
#SBATCH -P 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH --output=%j.out
#SBATCH --error=%j.err
module purge
# 思源
module load lammps/20220324-intel-2021.4.0-omp
# Pi
module load lammps/20230802-oneapi-2021.4.0
mpirun lmp -i in.lmp
Python¶
#!/bin/bash
#SBATCH -J Python
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
conda activate <ENV_NAME>
# source path/activate <ENV_NAME>
python test.py
Shell¶
#!/bin/bash
#SBATCH -J Bash
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
bash test.sh
Master 作业提交脚本示例¶
-
课题组服务器,提交的作业使用的 CPU 核数由 2 颗 CPU(Socket)分别部分提供时,计算速度会很慢(16 原子扰动胞 20 核计算,由原本的 5min 变成 60min,慢了 20 倍),终端使用 mpirun 运行作业的速度则是正常的(但只能在终端中运行 1 个命令,超过 1 个速度就会非常慢,大概率也会影响到队列中正在运行的作业)
-
不建议跨 node[1-2] 与 master 节点(这 2 种节点的 CPU 世代不同),也不建议跨 node[1-2] 节点,也不建议跨物理 CPU
-
使用 node[1-2] 中的 2 个节点
- 使用 node[1-2] 中的 1 个节点(不指定节点)
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH -n 40 # 或 #SBATCH --ntasks-per-node=40
#SBATCH -x master
#SBATCH --no-requeue # 取消集群断电重启后作业自动提交
- 使用 node[1-2] 中的 1 个节点(指定节点)
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=40
#SBATCH -w node2 # 指定节点
#SBATCH -x master # 排除指定节点;多个的写法 master,node1
#SBATCH --no-requeue # 取消集群断电重启后作业自动提交
- VASP
#!/bin/bash
#SBATCH -J VASP
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=16
#SBATCH -t 72:00:00
#SBATCH -o %j.out
#SBATCH -e %j.err
#SBATCH -x master
#SBATCH --no-requeue
ulimit -s unlimited
ulimit -l unlimited
mpirun vasp.5.std
- LAMMPS
#!/bin/bash
#SBATCH -J LAMMPS
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=16
#SBATCH -t 72:00:00
#SBATCH -o %j.out
#SBATCH -e %j.err
#SBATCH --gres=gpu:2
#SBATCH --no-requeue
ulimit -s unlimited
ulimit -l unlimited
# CPU 计算
mpirun lmp_cpu -i in.lmp
# GPU 加速
mpirun lmp_gpu -i in.lmp -sf gpu -pk gpu 2
- NEP & GPUMD(注:用 Slurm 调用 GPU 资源时,至少需要调用 1 个 CPU 核)
#!/bin/bash
#SBATCH -J GPU
#SBATCH -p gpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -t 72:00:00
#SBATCH -o %j.out
#SBATCH -e %j.err
#SBATCH --gres=gpu:1
#SBATCH --no-requeue
if [[ "$SLURMD_NODENAME" == 'master' ]]; then
gpumd
# nep
elif [[ "$SLURMD_NODENAME" == 'node2' ]]; then
gpumd_node2
# nep_node2
fi
- Python(在 slurm 文件中直接添加 conda activate 命令无效,报 conda init 相关错误)
#!/bin/bash
#SBATCH -J Python
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -t 72:00:00
#SBATCH -o %j.out
#SBATCH -e %j.err
#SBATCH --no-requeue
# 添加在 ~/.{ba,z}shrc 中的 conda initialize 内容
#--------------------- Conda ----------------------------
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/path/to/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/path/to/miniconda3/latest/etc/profile.d/conda.sh" ]; then
. "/path/to/miniconda3/latest/etc/profile.d/conda.sh"
else
export PATH="/path/to/miniconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
# 添加 conda activate 设置
conda () {
\local cmd="${1-__missing__}"
case "$cmd" in
(activate | deactivate) __conda_activate "$@" ;;
(install | update | upgrade | remove | uninstall) __conda_exe "$@" || \return
__conda_reactivate ;;
(*) __conda_exe "$@" ;;
esac
}
conda activate XXX
python test.py
作业状态检查¶
- 作业提交后,会生成
jobid.err和jobid.out文件err文件为空(大部分情况下),表示提交的作业未出错err文件不为空,表示提交的作业出错;需查看err文件中的出错提示,进行修改- 若
err、out文件出现以下内容,大概率为超算平台出现故障,请与相关负责人联系
# err 文件内容
/tmp/slurmd/jobid/slurm_script: line 24: mpirun: command not found
# out 文件内容
could not read file "/usr/share/Modules/libexec/modulecmd.tcl": no such file or directory
# Slurm 故障
slurm_load_jobs error: Socket timed out on send/recv operation
slurm_load_jobs error: Slurm backup controller in standby mode
相关问题¶
数据传输¶
-
参考:
- 数据共享与传输 - 上海交大超算平台用户手册 Documentation
- 提高数据传输速度(利用外部指令并发多个 scp/rsync 进程):数据传输技巧 - 上海交大超算平台用户手册 Documentation
-
超算进行数据传输一般在 data 节点上进行。超算传输节点
命令行¶
-
scp:Secure Copy,基于 SSH 协议进行文件传输,不支持增量传输
-
rsync:支持 SSH 协议或 rsync 协议、增量传输、支持本地和远程同步、支持断点续传
-
因安全策略升级,在集群的终端上不支持 scp/rsync 的远程传输功能,所以需要从用户本地终端使用 scp/rsync 命令:数据传输方案和传输节点 - 上海交大超算平台用户手册 Documentation
-
rsync 显示整体进度(不太好用):Overall Progress with rsync - Dave Dribin’s Blog
# scp 语法
scp [OPTION]... SRC DEST
scp [OPTION]... SRC [USER@]host:DEST
scp [OPTION]... [USER@]HOST:SRC DEST
# scp 参数
-p # 保留文件属性
-v # 详细输出
-r # 以递归方式复制
-q # 安静模式;不显示进度或错误消息
-P # 指定远程主机的端口号
# 示例
# 在超算传输节点终端,传输数据给 Master
scp -v -P 313 SRC [email protected]:DEST
# 在 Master 终端,传输数据给 Master
scp -v [email protected]:SRC DEST
# rsync 安装
brew install rsync # macOS 安装 3.X.X 新版本
# rsync 语法
rsync [OPTION]... SRC DEST
# 单个冒号:通过 ssh 或 rsh 协议连接远程主机
# 若 ~/.ssh/config 中已为 [USER@]HOST 设置了别名和配置,则其可用别名简化
rsync [OPTION]... SRC [USER@]host:DEST # 等效于上传文件到远程服务器
rsync [OPTION]... [USER@]HOST:SRC DEST # 等效于从远程服务器下载文件
# 两个冒号:通过 rsync 协议连接远程主机的 rsync 守护进程
rsync [OPTION]... [USER@]HOST::SRC DEST
rsync [OPTION]... SRC [USER@]HOST::DEST
# 示例
# 在超算传输节点终端(Pi 可以,思源不可以),传输数据给 Master
rsync -avuP --human-readable -e "ssh -p 313" SRC [email protected]:DEST
# 在 Master 终端,传输数据给 Master(Pi、思源都可以)
rsync -auvP --human-readable [email protected]:SRC DEST
# rsync 参数
-v, --verbose # 详细输出
-q, --quiet # 安静模式
-a, --archive # 归档模式,表示以递归方式传输文件,并保持所有文件属性,相当于 -rlptgoD
-r, --recursive # 递归模式
-l, --links # 保持符号链接的属性
-L, --copy-links # 复制符号链接指向的实际文件/目录,而非符号链接
-p, --perms # 保持文件权限
-t, --times # 保持文件时间戳
-g, --group # 保持文件所属组
-o, --owner # 保持文件所有者
-D, --devices # 保持设备文件(块设备和字符设备)
-z, --compress # 传输时进行压缩处理
-n, --dry-run # 不实际运行,显示哪些文件将被传输
-delete # 删除那些 DST 中 SRC 没有的文件
-exclude # 排除指定的文件或目录
-include # 只包括指定的文件或目录
--existing # 只更新目标路径中已存在的文件
-e, --rsh=COMMAND # 指定使用 rsh、ssh 方式进行同步
-u, --update # 仅进行更新
--human-readable # 显示输出文件大小以 KB、MB、GB 等表示
--progress # 显示传输进度
-P # --partial --progress 的简写,不仅显示传输进度(单个文件),还会在传输中断时保存部分传输的数据,方便下次继续传输
-e "ssh -p 313" # 指定 SSH 连接的端口号
--info=progress2 # 显示整体的传输进度,避免与 -v --progress 参数一起使用
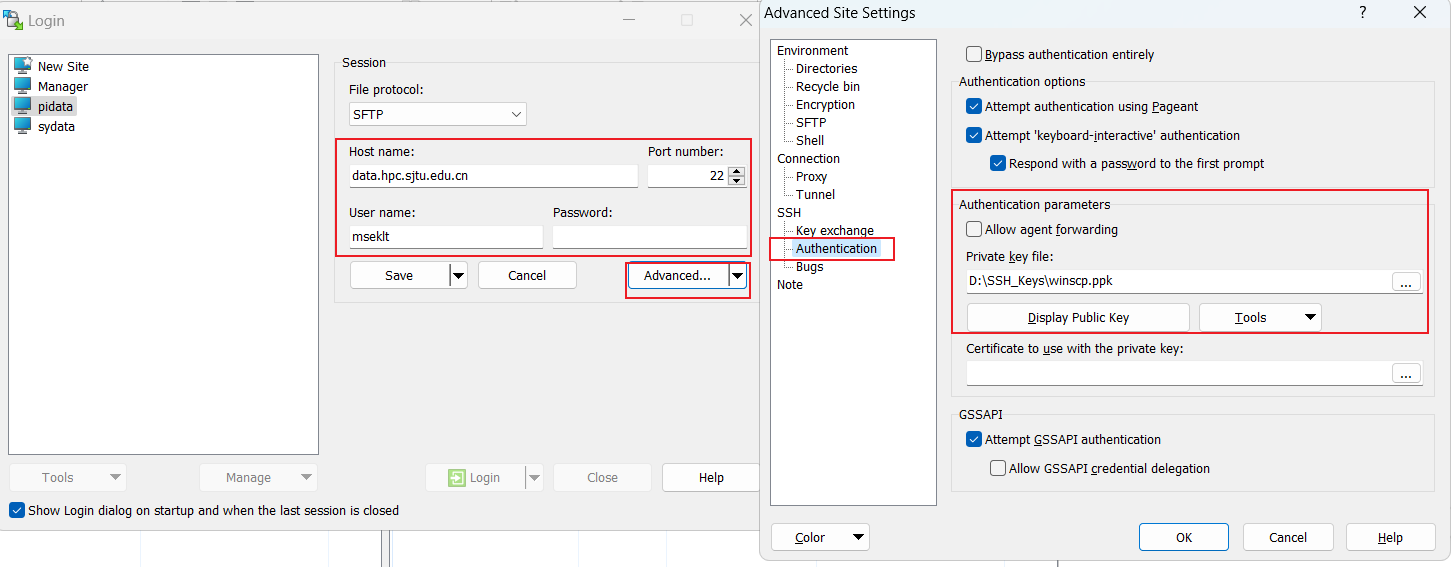
客户端¶
软件主要使用 WinSCP;免密登录操作见下图:
Manager 与超算间的数据传输¶
- 上传与下载:孔老师写的 upload 与 download 脚本
- Manager 与 Pi:
upload -s P或将P改成H或h - Manager 与思源一号:将
P改成s
- Manager 与 Pi:
# 上传
upload -s P manager/path pi/path
upload -s s manager/path siyuan/path
# 下载
download -s P pi/path manager/path
download -s s siyuan/path manager/path
程序编译/安装¶
- 在超算上编译程序,由于登录节点资源有限,需在计算节点上进行,需申请临时计算节点(一个核即可)
-
posconv、NumNei、latgen、dumpana、atomsk
-
VASP.5.4.4、VASP.6.3.0、HDF5、VTST:VASP 编译 - Wiki of NES Lab
-
超算高版本 glibc 编译:glibc - 上海交大超算平台用户手册 Documentation
-
超算上没有 mpi4py(需自己安装):Mpi4py - 上海交大超算平台用户手册 Documentation
-
源码编译一般步骤(编译前,需理解 Makefile 文件中的命令含义!)
交我算常见问题总结¶
以下是使用 “交我算” 过程中可能遇到的常见问题总结:
充值/费率
- 计费系统 (HPC 账号和密码登陆):https://account.hpc.sjtu.edu.cn
- 充值方法:https://net.sjtu.edu.cn/info/1244/2392.htm
- 费率问题:请用交大邮箱发送至 [email protected] 咨询
致谢模版
- “交我算” 用户在发布科研成果或论文时,应标注 “本论文的计算结果得到了上海交通大学交我算平台的支持和帮助”(The computations in this paper were run on the π 2.0 (or Siyuan Mark-I) cluster supported by the Center for High Performance Computing at Shanghai Jiao Tong University). 论文发表后,欢迎将见刊论文通过邮件发送到 [email protected]。
登录问题
- 连不上集群: https://docs.hpc.sjtu.edu.cn/faq/index.html#id6
- 登录常掉线:https://docs.hpc.sjtu.edu.cn/login/index.html#id10
- HPC studio 登录问题:https://docs.hpc.sjtu.edu.cn/studio/faq.html#hpc-studio-proxy-error
- Jupyter、Rstudio 连接提示需要输入密码:https://docs.hpc.sjtu.edu.cn/studio/faq.html#jupyterrstudio
排队问题
- status 监控系统:https://status.hpc.sjtu.edu.cn,该系统包含各队列上线节点数、排队数、作业数等信息
- π集群排队问题:思源一号可用 CPU/GPU 资源更多,欢迎使用思源一号。
- 通过 squeue 查看作业,NODELIST(REASON) 为 resources/priority 表示正常排队,AssocGrpNodeLimit 表示欠费。
作业问题
- 报错作业咨询,请将用户名、作业 ID、路径、作业脚本名邮件发至 [email protected]。
- NodeFail:计算节点故障导致作业运行失败,重新提交作业即可,失败作业的机时系统会自动返还。
- 运行程序时提示缺少 xxx.so 文件或者显示作业被 kill:如果是在登录节点出现该报错,请申请计算节点再做尝试。
软件安装问题
- 如何在集群上安装软件:https://docs.hpc.sjtu.edu.cn/faq/index.html#id16
- 商业软件问题:https://docs.hpc.sjtu.edu.cn/faq/index.html#id17
数据传输问题
- \(\pi\) 集群传输至思源一号:https://docs.hpc.sjtu.edu.cn/transport/index.html#id4
常用链接
- HPC 网站:https://hpc.sjtu.edu.cn
- 用户文档:https://docs.hpc.sjtu.edu.cn
- 超算用户简明手册:https://docs.hpc.sjtu.edu.cn/_static/hpcbriefmanual.pdf
- 集群实时利用率:https://account.hpc.sjtu.edu.cn/top
- 公众号/视频号:交我算